Reducing Costs and Complexity Through Infrastructure Consolidation
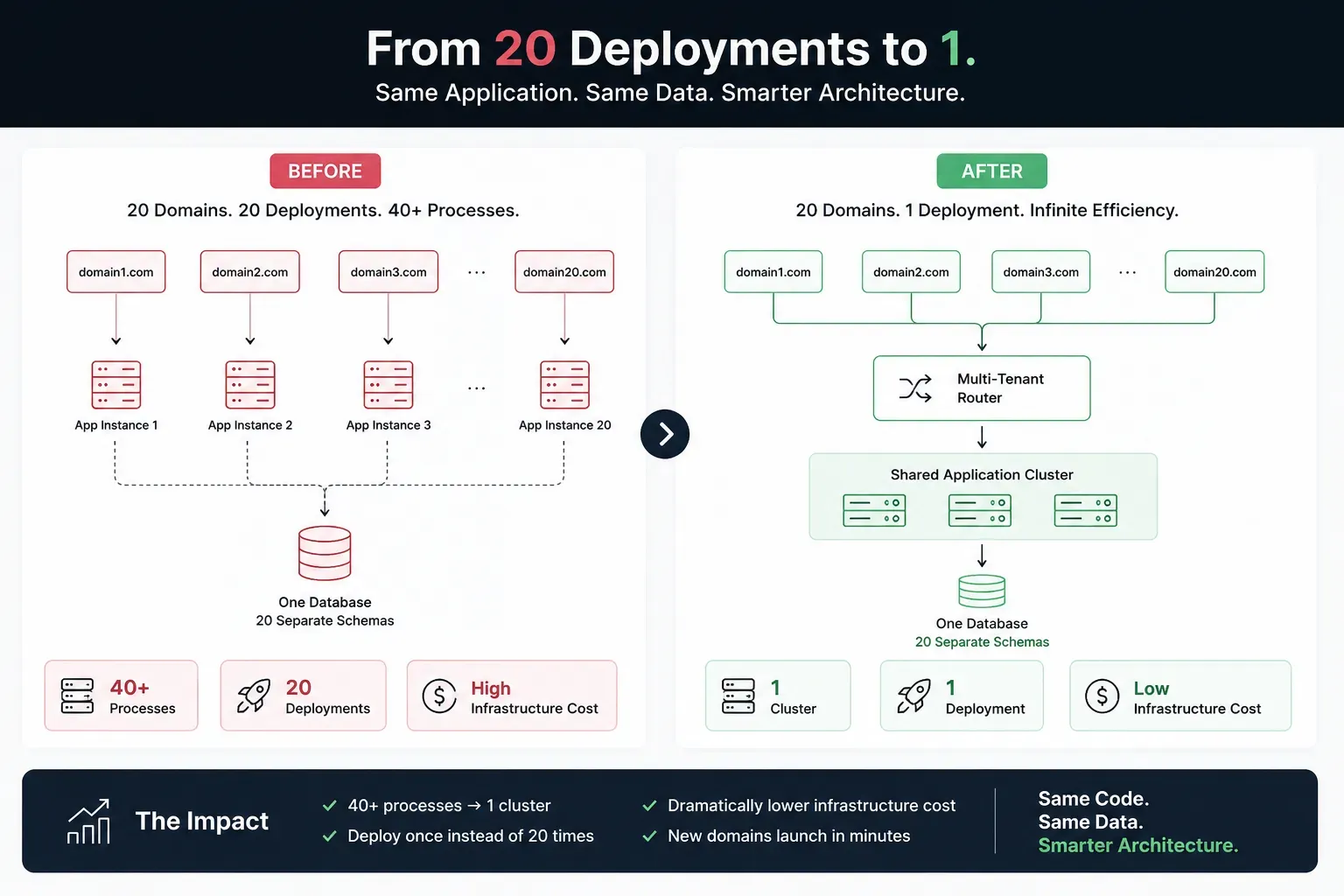
Re-architected a fragmented, high-cost infrastructure—consolidating 40+ independent server processes into a single, scalable multi-tenant system. This transition slashed monthly operational costs while enabling the platform to support thousands of concurrent users across multiple domains without additional overhead.
The Situation: Working, But Wasteful
A platform was deployed across 20 separate domains, each with an identical codebase. Here’s how it happened:
The client launched on the primary domain. Then requested the same application on a second domain. So we deployed it again. Same code, separate servers. This repeated incrementally—20 times—until we had:
- 40+ independent server processes (frontend + backend per domain)
- 1 shared database instance with 20 separate schemas (one per domain)
- A manual deployment process: push updates to 20 different servers
- Infrastructure costs that made no business sense
From the client’s perspective: everything worked perfectly. No data leaks. No downtime. No complaints.
From an engineering perspective: we were running 20 complete copies of identical code.
The Problem: Not Broken, Just Duplicated
The infrastructure wasn’t broken—it was redundant.
The data isolation was already happening at the database schema level. Each domain had its own schema, and the application connection logic knew which schema to query based on which domain it was deployed on.
But the duplication existed at the container layer. We were running 20 separate clusters when one cluster could serve all 20 domains if we just routed based on the incoming domain name.
The hard question nobody had asked: Why are we running identical code in 20 different places?
The Solution: Two Strategic Changes
Instead of building something new, I identified that the duplication existed in two layers—and fixed each one.
Phase 1: Frontend Consolidation
The Next.js frontend had no client-side state. Each domain had its own frontend deployment, but they were identical—the only difference was hardcoded API routes (domain.com/api, domain2.com/api, etc.).
The fix was simple: change all API requests to relative paths (/api instead of domain.com/api).
Since the browser makes requests relative to the current domain, this one change meant:
- One Next.js instance could serve all 20 domains
- No state management needed—the Host header (browser’s current domain) naturally routed each user to the correct backend
Result: 20 frontend processes collapsed into 1 instance.
Phase 2: Backend Multi-Tenancy
The backend API needed to become tenant-aware. Each request now had to:
- Read the Host header (incoming domain name)
- Determine which schema that domain maps to
- Query the correct schema for that domain
- Return the data
This required rewriting the backend logic to:
- Accept the Host header as a tenant identifier
- Route database connections to the correct schema based on domain
- Ensure all queries, mutations, and lookups operated on the correct schema
The database structure didn’t change—schemas were already separated. But the application layer now had to actively read the incoming domain and enforce which schema to use.
Execution
Both phases were executed with zero downtime:
- Deploy the new frontend pointing to the new multi-tenant backend
- Migrate domains one at a time to the new infrastructure
- Old servers stayed running until all domains were verified on the new cluster
- Retire old infrastructure once migration was complete
Results
Infrastructure Footprint
- From: 40+ independent server processes
- To: 1 high-availability cluster
- Result: Hosting costs slashed dramatically
Deployment Pipeline
- From: Manually push updates to 20 servers
- To: Deploy once, serve all 20 domains
- Result: 20x reduction in deployment complexity
Operational Agility
- Adding a new domain went from: “spin up servers, deploy code”
- To: “add a schema, update DNS”
- New domains go live instantly
Reliability
- Previous: 20 single points of failure (one server per domain)
- Now: HA cluster with redundancy, failover, and auto-scaling
Key Insight
The biggest inefficiencies often hide in plain sight because they work. We had built something that functioned perfectly, so nobody questioned whether it made sense.
The best infrastructure optimizations aren’t always about building something new. Sometimes they’re about removing what should never have been duplicated in the first place.
Strong infrastructure decisions don’t just save money—they fix the business’s ability to operate efficiently.
Let's build something like this together
I partner with founders and product teams to architect and ship high-impact systems. Reach out and let's talk.